LLM Digital Twin
Fine-tuning a model to contain my memories, personality, and preferences. Data gathered from an iPhone, trained using local compute (2 Mac Studios), to run on a 7b model (Mistral) that is capable of running inference on an iPhone.
Apple MLX (LoRA)
100k Q&A examples
Data, training, evals, alignment
2 weeks
2025
Challenge
I wanted an always-up-to-date “digital twin” that could answer questions exactly the way I would—from personal anecdotes to my latest calendar plans—without ever leaving my devices or exposing raw data to the cloud. Existing tools were either heavyweight (server-side LLMs) or too limited (on-device chatbots). The real hurdle: turning gigabytes of iPhone data (Photos, Messages, Mail, Calendar, Location, Web history…) into a lightweight, privacy-preserving model that could run in real time on an iPhone-class chip.
Results
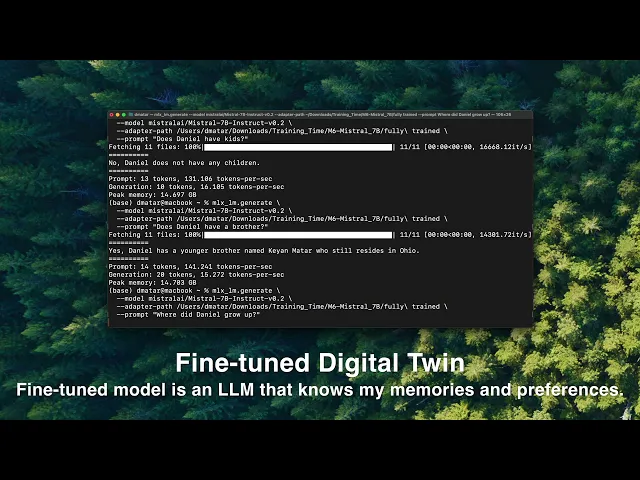
MeModel: A Digital Daniel—a 7-B parameter model that mirrors my personality, knowledge and writing style, running locally on my iPhone with <1 s first-token latency.
Zero-cloud footprint: all raw data stays encrypted on my personal hardware; only the distilled weights live on the phone.
Seamless updates: new memories appear in answers within hours, not weeks.
Foundation for more: this pipeline can power future user simulations in an AI first computing world.
90%
Accuracy on personal evals
7b
Parameter fully tuned model
Mac Studio
Local compute used for fine-tuning


Process
Data Extraction & Normalisation
Used Apple’s data-export APIs to pull each app’s history, then converted every stream into unified JSON schemas.
Synthetic Q&A Generation
Prompted a base LLM to read those JSON slices and auto-write ~100 k conversational Q&A pairs that reflect my tone, memories and relationships.
Dataset Curation
Applied heuristics for balance (time, topic, sentiment) and stripped sensitive fields; encrypted everything at rest on two local Mac Studios.
Fine-Tuning Pipeline
Split into train/val/test, then fine-tuned a Mistral-7B model in Apple MLX with LoRA adapters and safesensors weight format.
Quantised to 4-bit (SmoothQuant) for on-device inference.
Continuous Refresh
Nightly cron job exports the day’s new JSON, regenerates incremental Q&A, and performs a quick LoRA refresh so the model evolves with me.
Deployment
Packaged the quantised weights and adapters into an iOS inference app; integrated a retrieval layer for very recent memories (<24 h) to avoid constant re-training.
