Personal Deep Research
Imagine “LLM Deep Research,” but pointed inward: the model searches your iPhone’s personal data to answer questions about you.
By pairing on-device retrieval (RAG) with an LLM, this prototype resurrects personal memories on demand and hints at the future of truly personal assistants.
Also see the Product Design side of the project.

Compute used
Self-built GPU Rig, 30 TFLOP (1:64)
Database
SQL
Virtualize you
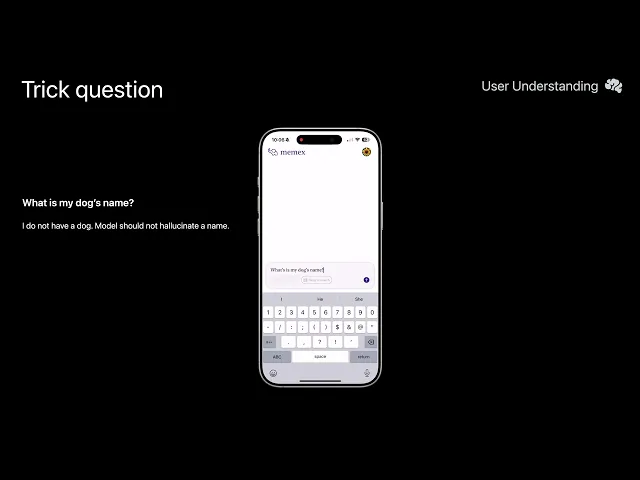
Challenge
Designing a system capable of deeply understanding and responding to user queries required integrating heterogeneous data sources, personal context, and temporal nuance—all while preserving privacy. The key challenge was combining large language models (LLMs) with retrieval mechanisms that could operate efficiently on-device and synthesize insights in a way that felt both accurate and personal.
Results
The resulting system successfully merges on-device RAG with LLM-powered reasoning, enabling rich, context-aware answers grounded in personal data. It transforms raw streams into structured knowledge and anticipates user needs through self-questioning pipelines, paving the way for intelligent, memory-augmented personal assistants that feel truly aware.

Multi-Stage LLM Pipeline for Structured User Insights
The User Understanding system processes user data through a multi-stage pipeline that transforms raw information into structured knowledge. When data streams are ingested, they undergo a backfill process that extracts insights across various dimensions using an LLM. These insights are stored as structured observations in databases, creating a rich knowledge foundation.

Self-Questioning RAG Pipeline for Insight-Rich Retrieval
At query time, the system leverages a sophisticated RAG pipeline combining BM25 lexical search, embedding-based semantic similarity, and temporal context expansion. What makes this architecture powerful is its self-questioning mechanism that proactively generates and answers questions from multiple perspectives, creating a network of pre-computed insights. When user queries arrive, this approach enables retrieval of both raw evidence and previously synthesized observations, allowing for rich responses.